GeoClassiffr
In my first gap year after high school, I spent more time than I would like to admit on Google Maps. I would be mindlessly driving on Google Streetview, or I would just be scrolling through cities, seeing what kind of establishments they had in the different areas. I also got very much in GeoGuessr, a game where you get thrown somewhere in world on Google Streetview, and your task is to guess the location. After playing it for a while, I grew out of it and started doing other stuff. Recently however, I got sucked in again. After playing for a week I wondered how well a CNN classification network would do on some of the locations, so I started building.
The plan was to create a network capable of guessing which country an image is taken in. I decided to only include official Geoguessr country maps, totalling 85 different countries around the world.
The first, and probably the hardest part, was gathering a dataset. After searching online I managed to find some datasets, however they were either too small, imbalanced or had the game UI visible on the screen. At first I planned to make a dataset by hand, but after about 4 hours I realized this would not be feasable so I started working on a script which would automatically start a round, take a screenshot, make a (random) guess and go to the next round. After running this script a couple days I managed to obtain 300 unique images per country, totalling about 25,000 1600x900 images, coming in at 60GB. You can download the dataset on Huggingface.

After creating the dataset, I decided to use a ResNet backbone for the classifier, trying out ResNet-34, ResNet-50, ResNet-101 and ResNet-152 to see what the differences in performance would be. Since the dataset images are 1600x900, I randomly crop a 448x448 patch from the image and resize it to 224x244 to feed it into the network. To find optimal learning rate, dropout rate, weight decay and scheduler settings, I used Optuna as an optimization library, early stopping a run when test loss does not decrease for three consecutive epochs.
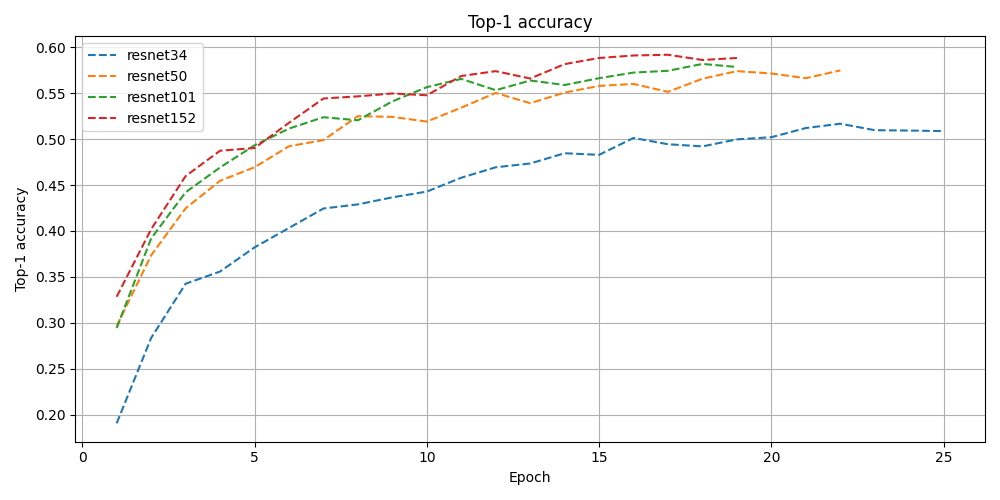
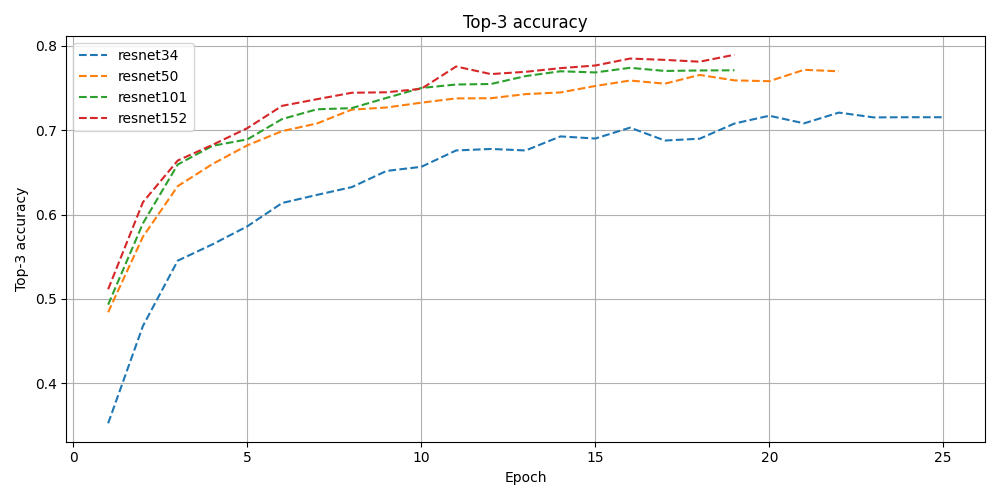
The following results all come from the ResNet-101 model, all results can be downloaded here, or are available on the Github. First I wanted to display all images, together with their predicted- and their true class. Some interesting examples of this are found below. As can be seen in these examples, the model makes some natural mistakes such as confusing Norway for Finland, or Serbia for Greece. However, it correctly predicts Guatemala from just some bushes and pavement, perhaps the pole that can be seen is unique to Guatemala and the model learned to recognize that as a Guatemala feature.




Next, I wanted to know which classes were easiest to predict for the model and which ones were the hardest. To do this, I created a sklearn classification report, a table of which can be found below (some places are omitted to save space. The full csv file can be found in the total results dump.). Quite unsurprisingly, relatively unique countries turned out to be easier for the network, as evidenced by the high scores of Iceland, Malta, Kyrgyzstan and Lebanon, to name a few. Also, European countries score notably worse than other countries, which is quite logical when considering the fact that 1. There is more StreetView coverage in these places, so more border regions will be mapped, allowing for more confusion, and 2. most neighboring European countries do look quite alike, considering their often shared history.
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Albania | 0.56 | 0.72 | 0.63 | 61.0 | Bangladesh | 0.63 | 0.76 | 0.69 | 59.0 |
| Bhutan | 0.83 | 0.80 | 0.81 | 60.0 |
| Bolivia | 0.63 | 0.62 | 0.62 | 60.0 |
| Botswana | 0.67 | 0.82 | 0.74 | 60.0 |
| Brazil | 0.43 | 0.33 | 0.37 | 60.0 |
| Denmark | 0.42 | 0.37 | 0.39 | 60.0 |
| Ecuador | 0.58 | 0.52 | 0.55 | 60.0 |
| Iceland | 0.85 | 0.87 | 0.86 | 60.0 |
| Indonesia | 0.32 | 0.37 | 0.34 | 60.0 |
| Kyrgyzstan | 0.74 | 0.87 | 0.80 | 60.0 |
| Lebanon | 0.95 | 0.98 | 0.97 | 60.0 |
| Netherlands | 0.42 | 0.38 | 0.40 | 60.0 |
| Pakistan | 0.68 | 0.75 | 0.71 | 60.0 |
| Qatar | 0.83 | 0.89 | 0.86 | 60.0 |
| SouthKorea | 0.73 | 0.78 | 0.76 | 60.0 |
| SriLanka | 0.80 | 0.85 | 0.82 | 60.0 |
| Sweden | 0.36 | 0.40 | 0.38 | 60.0 |
| UnitedStates | 0.58 | 0.60 | 0.59 | 60.0 |
| Zimbabwe | 0.65 | 0.60 | 0.63 | 60.0 |
| macro avg | 0.56 | 0.59 | 0.57 | 60.0 |
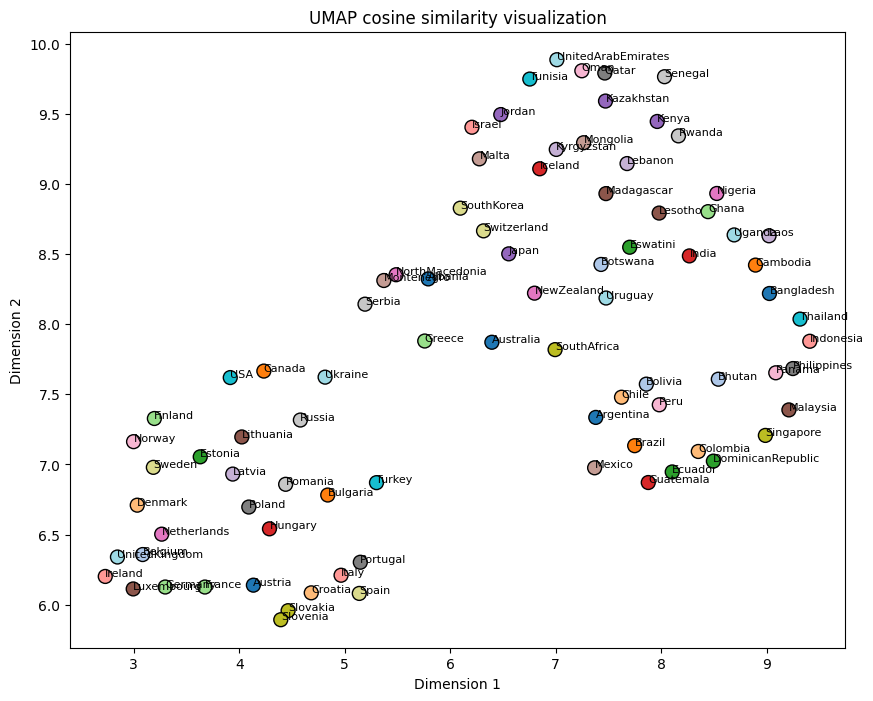
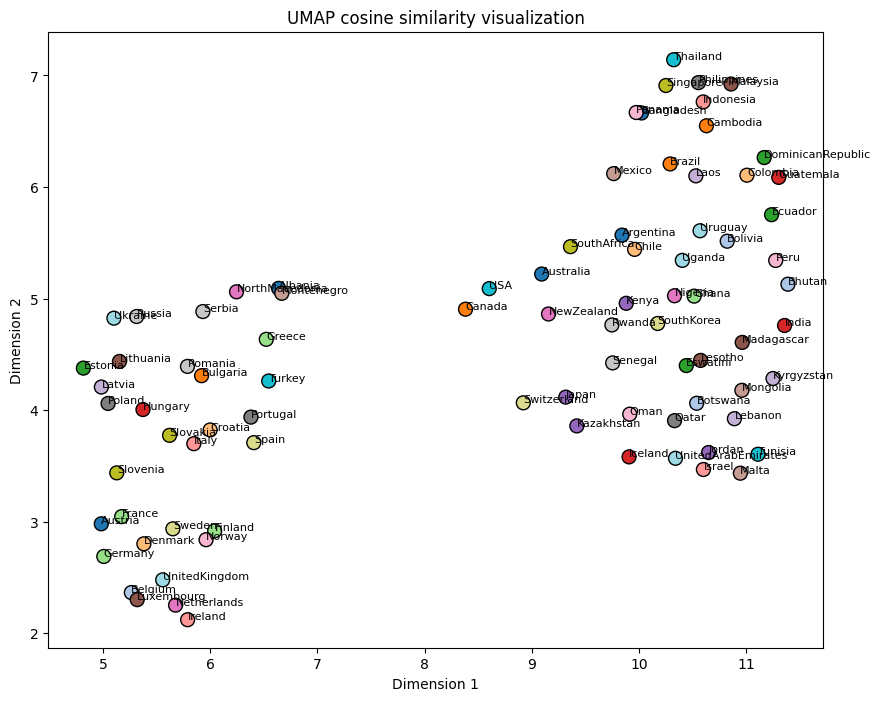
Finally, I wanted to identify which countries the model considered most similar. To achieve this, I created 2-dimensional t-SNE and UMAP embeddings using the rows of the confusion matrix. Based on a ChatGPT suggestion, I also generated an alternative version where I calculated the cosine similarity of the confusion matrix, resulting in a matrix containing information about the similarity between different countries. After dimensionality reduction on this matrix, UMAP turned out to give a more intuitive representation. As can be seen, most European countries are all clustered on the lower left side, with the Netherlands, Belgium and Denmark being especially close. The Nordic countries are also clustered together, as well as the Baltic countries. The Middle Eastern countries are all nicely clustered at the top, and tropical Asian countries on the right side. The ResNet-152 UMAP visualization below the ResNet-101 I find especially satisfying. On the left side Western European countries are clustered together, slowly moving more towards Eastern European countries when following the positive second dimension. On the other side you have Asian countries around the equator together, which apparently are similar to tropical Latin American countries such as the DR an Brazil.
The model seemed to be overfitting after some time, so perhaps with a larger dataset the model could become better, I might do that in the futute. I also started on a US state dataset to create a state classifier, which I might publish in the future. All results, as well as the training and evaluation code can be found on my Github. The results can also be downloaded here, and the dataset used can be found on Huggingface. The pre-trained models are also available on Huggingface.