LLM plays codenames
A month or so ago I saw a tweet of someone claiming some newly released LLM was 'THE FINAL MODEL'. They pointed out that the model was apparently very good at playing a game called Codenames. From Wikipedia: 'two teams compete by each having a "spymaster" give one-word clues that can point to specific words on the board. The other players on the team must attempt to guess their team's words while avoiding the words of the other team as well as an assassin square; if the latter is selected, then the team which selected it instantly loses. Victory is achieved when one team guesses all of their spymaster's assigned words' . Having played this game myself a fair bit, I wondered just how good various LLMs would perform playing the game, so I decided to test it out.
I happened to have some credits left on my account on fal.ai, so I decided to use their fal-ai/any-llm endpoint for the different LLMs. After implementing the game and tweaking the prompts for the spymaster and the guesser a bit, I started the simulation and went to bed. The next morning I had no money left in my account, but I was a couple hundred simulated games richer.
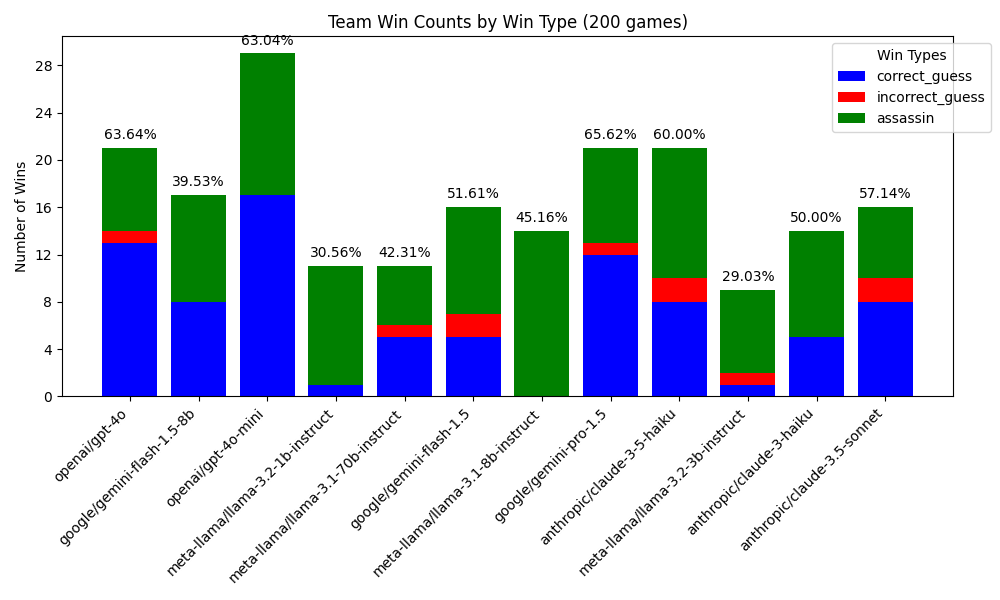
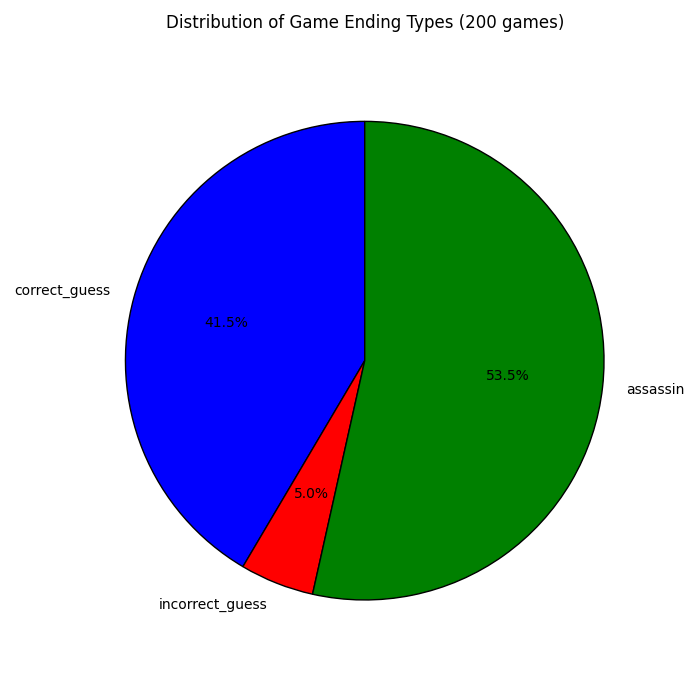
The first thing I obviously wondered was which model was the best. After giving ChatGPT an example of what the game log object looked like and asking to plot the win rates by win type, I got the following plot. The first thing I noticed was the fact that many games were ended by the other team guessing the assassin word. Anecdotally, when playing with humans this occurs maybe 5% - 20% of all games. Between LLMs, however, it seemed to happen around one in every two games! After plotting the distribution of the different game endings, this was indeed the case. Even with more specific spymaster prompting highlighting that the assassin word must be avoided at all cost, the distribution did not change much.
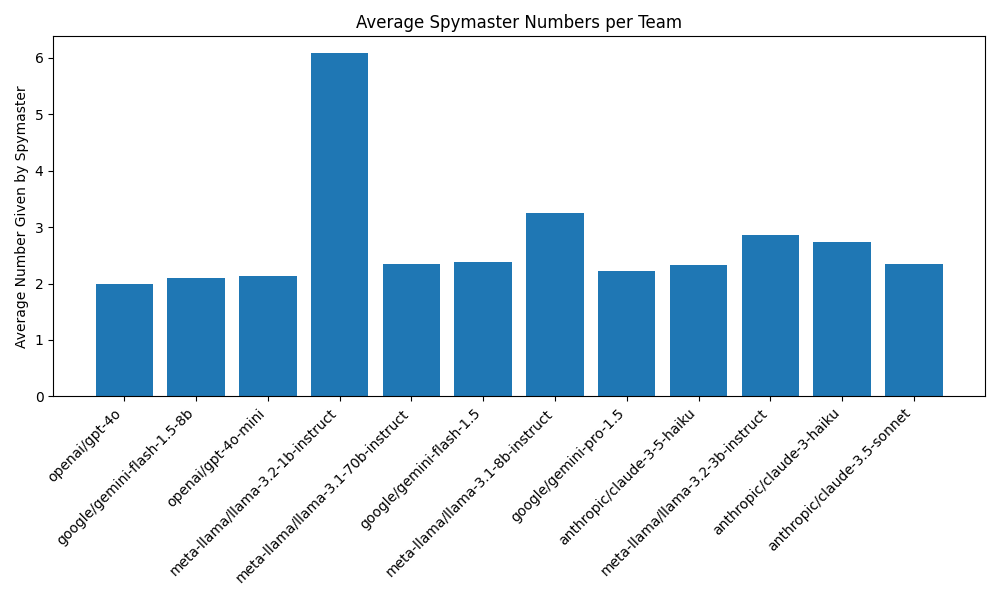
Next, I wanted to know more about the strategies each model used. Since LLMs are supposed to be such geniuses, I assumed some impressive strategies with clever word hints would be developed. However, as can be seen from the figure below, the strategies were mostly very boring. The models with the highest win rates on average only provide about 2 words per clue. If this was not bad enough, the models also only had a guess accuracy of a bit more than 65%. These two facts combined made for an average game duration of roughly 10 turns. This is especially atrocious when you realize that each team only has 8 or 9 cards in the first place.
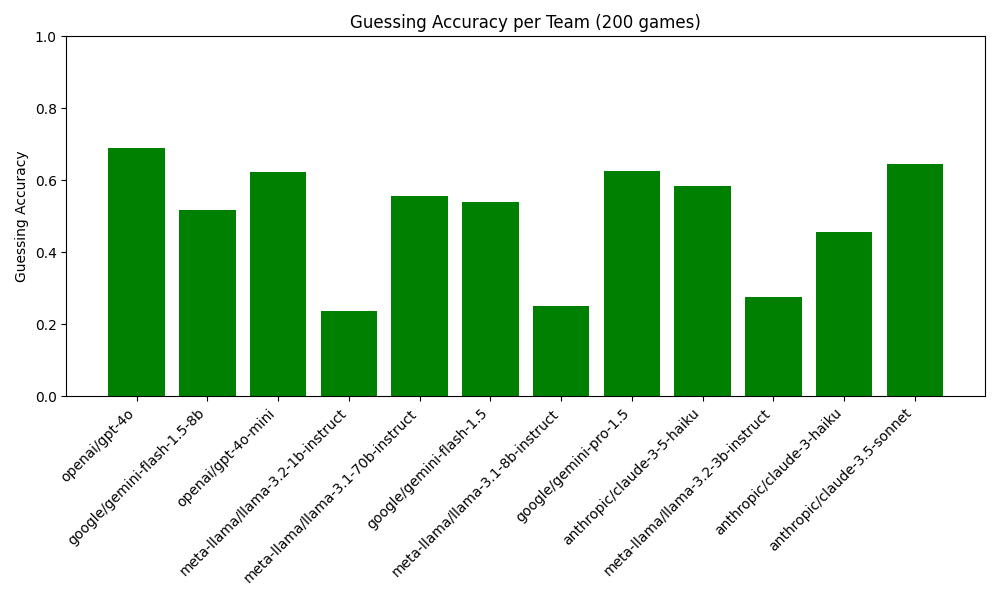
Before starting with this, I hoped to see that the models would think of clever clues where they would tick off 4 words at a time. Then, I planned out, I would mix the team where each team consists of two different models. With this I wanted to see if the different models would be able to understand and decipher the clues thought of by the other model. Unfortunately, the homogeneous teams were already so bad that this second phase of the experiment does not even make sense to make.
To conclude, it turns out that the LLMs I tested all suck at Codenames. While some models performed better than others, even the top performing models would not be a match for even a beginning 15 year old player. While the models might be able to play a bit better with more careful prompting and some potential other hacks, I do not have much faith in AI playing Codenames for now (and I am out of fal.ai money).
For the code and plotting scripts, see my Github.